Self-Repellent Random Walks on General Graphs
Achieving Minimal Sampling Variance via Nonlinear Markov Chains
By: Vishwaraj Doshi, Jie Hu, Do Young Eun
Why?
- Graphs are random ($\pm \varepsilon$)
- fully explored graph $\rightarrow$ understanding of the topology of the graph
- Seeing the same state twice is a waste of time
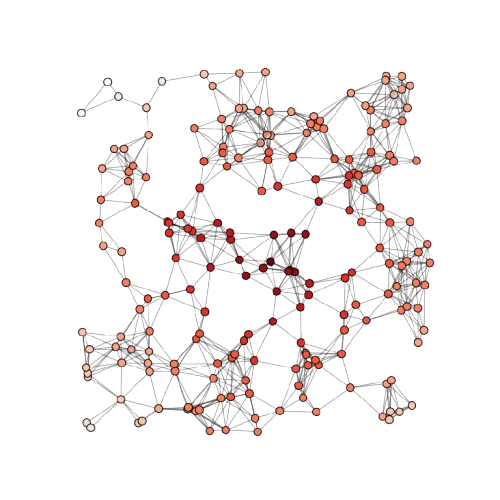
Why ⁉️
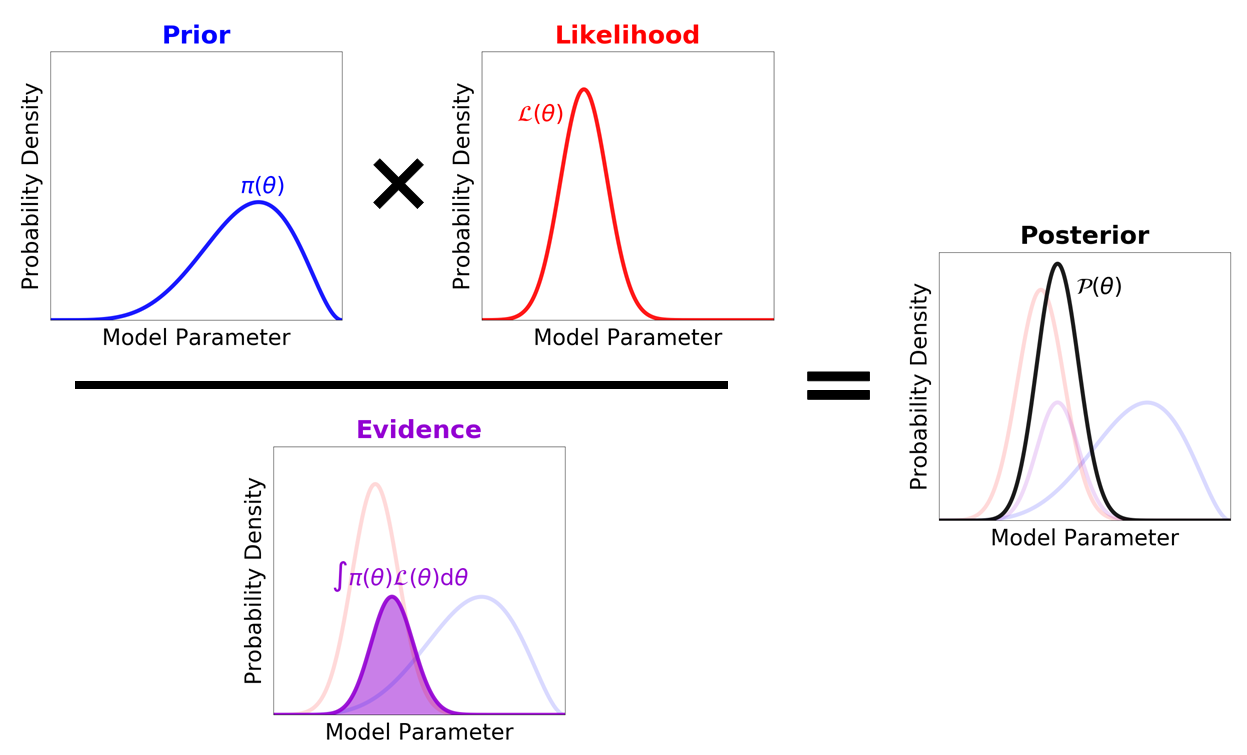
however they have their own issues
- Slow convergence time
- Correlated sampling
Main Challenge 🛑

Proposed Solution 💡
but obviously, we need to massage this a little bit, because if it were trivial, someone else woulda did it!

Formal Goal 🥅

Assumptions 🧪

Methodology ⚙️
- adj. $\cal A$
- neighboors $\cal N$
- deg. (degree of node)
- $\Sigma$ probability simplex over $\cal N$
- $P$ transition probability
Methodology ⚙️
SSRW Transition Kernel
Methodology ⚙️
Non Linear Markov Chains
This is where they vary from traditional "linear" kernels who are only dependent on the Markov Chain.
\[x_n = \frac{1}{n+1} \sum^{n}_{k=0} \delta_{X_k}\]
where $\delta$ is the measure of change of an entry
Methodology ⚙️
Tunable Parameters
If we set this parameter to be too high, we might be too strict in our selection of new states.
Similarly if we set this parameter to be too low, we will basically select random states
Proof✍️
- Computational coplexity
- ~ Optimiality
Proof✍️
Which is incredible!
Conclusion ✅
- to do
- to understand
- to read
I don't blame the authors for this though, what they did was complex and hard. I came into this paper without the background required to understand it.

Thank + Questions
Thanks for listening, please direct any questions to wwu@diegollanes.com