deep reinforcement learning
by diego llanes
what is reinforcement learning?
there are many different types of ML that we are familiar with
- supervised learning
- unsupervised learning
- reinforcement learning (RL)
what is reinforcement learning?
what separates RL from these other branches of ML?
typically in ML, you have:
- inputs: $x$
- targets: $y$
except in the case of unsupervised! (only $y$)
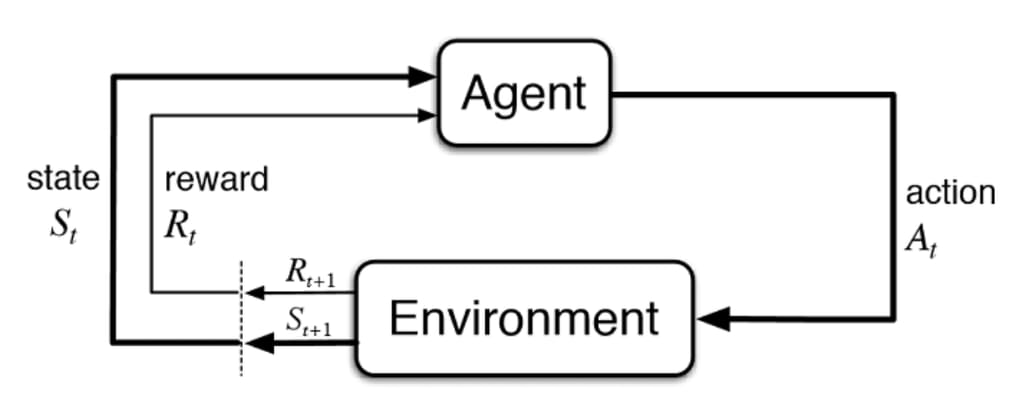
what is reinforcement learning?
short answer: it's a little less clear, it is a little less cut and dry.
expected outcomes
- when to use drl (why)
- basic familiarity with drl keywords
- a gained appreciation for the field
- where to start (libraries)

keywords
- state-action tuples
- an environment
- an agent
- a reward function
keywords['observation-space']
an observation space $(Y)$ is the set of features about the state that your controller has access toan important thing to note is that, lots of the time you don't have the access to the full state $(X)$
these spaces can be continuous, discrete, or even pictorially!
keywords['action-space']
your action space $(U)$ is the set of all possible actions

keywords['state-action']
they are tuples for a timestep $t$ that contain a state and an action for that cooresponding timestep
keywords['environment']

\[(s_t, a_t) \rightarrow s_{t+1}\]
keywords['agent']
in deep reinforcement learning $\pi$ is a neural network, but in more traditional approaches, $\pi$ is a table

why drl???
drl becomes useful when you are operating in a non-differentiable environment
why drl???
acrobot our reward function looks something like the following:

why drl???
these problems naturally lend themselves to being effectively solved by these techniques!
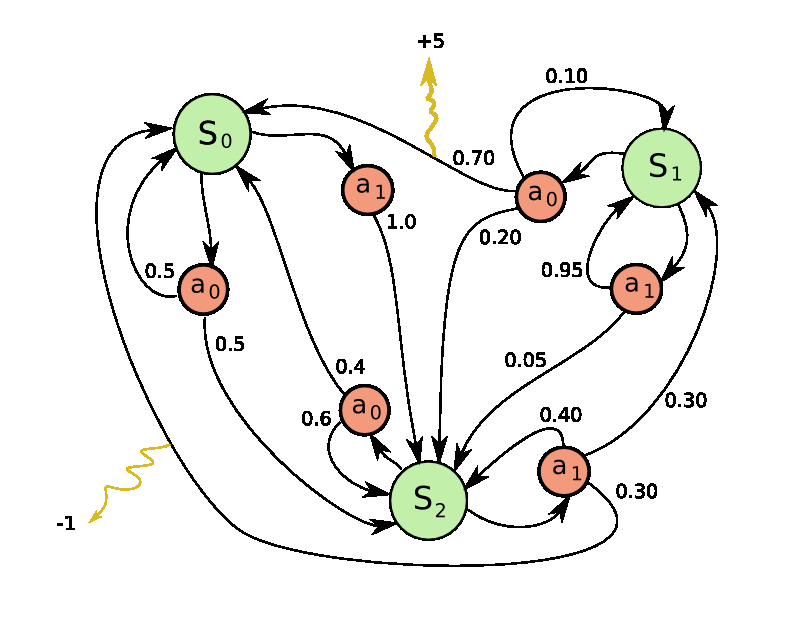
Why DRL??? (ABCD)
Which of the following might be an area wherein DRL could be useful?
- Sorting lists
- Fine-tuning language models
- Basic arithmetic operations
- Image compression
Why DRL??? (ABCD)
Which of the following might be an area wherein DRL could be useful?
- Sorting lists
- Fine-tuning language models
- Basic arithmetic operations
- Image compression
Why DRL??? (ABCD)
Which of the following might be an area wherein DRL could be useful?
- Sorting lists
- Fine-tuning language models
- Basic arithmetic operations
- Image compression
where do I even start???

where do I even start???
just to be clear this stuff is stolen straight from skrl
